Gemini 3.1 vs GPT-5.4 vs Claude Opus 4.7: Which Is the Best AI Model in 2026?
Three giants. Three different philosophies. And one question every tech professional, developer, and manager is asking right now: what is the best AI model in 2026?
In this article, you’ll find a technical, hands-on comparison between Gemini 3.1 (Google DeepMind), GPT-5.4 (OpenAI), and Claude Opus 4.7 (Anthropic), the three most advanced large language models available today. We use benchmarks recognized by the scientific community, real-world use cases, and a cost-benefit breakdown to help you make the right call.
My Experience (From the Author)
I tested all three seriously as a manager who uses AI daily. For structuring processes and deeper analysis I ended up adopting Claude Opus — especially via Claude Code in the terminal, where it really shined for automating reports and internal scripts. GPT still stays in rotation for free-flow ideas and quick rough drafts. Gemini became my go-to for classifying new tickets coming in by email — it's the most accurate one for my domain and the cheapest of the three. Each one has its place, and the mistake is trying to use a single one for everything.
Why This Comparison Matters in 2026
The AI model market has shifted radically over the last 18 months. If picking between GPT-4 and Claude 3 used to be a matter of personal preference, today the gap between the three market leaders is technical, strategic, and financial.
Companies are wiring AI into mission-critical workflows, from code generation to legal review, from customer support to scientific research. The wrong model means wasted tokens, sloppy answers and, in production, failures that get expensive fast.
The Three Models in 2026: An Overview
Gemini 3.1, Google’s Multimodal Workhorse
Gemini 3.1 is the latest evolution of the Gemini Ultra family. Built by Google DeepMind, it ships with native multimodality — it processes text, images, audio, video, and code inside the same base model, with no external adapters.
Its standout feature is the 2-million-token context window, which lets it handle entire documents, full codebases, or long conversation histories without losing coherence. For teams sitting on mountains of unstructured data, this is a genuine game-changer.
Strengths:
- Native multimodality (video, audio, image, text, code)
- Market-leading context window (2M tokens)
- Native integration with the Google ecosystem (Search, Workspace, Cloud)
- Strong at reasoning over tabular data and spreadsheet analysis
Weaknesses:
- Less consistent than Claude on long, complex instruction following
- High cost on long-context queries
- Textual creativity below GPT-5.4 and Claude Opus 4.7
GPT-5.4, OpenAI’s Generalist
GPT-5.4 is the latest version of the GPT-5 family, released by OpenAI in early 2026. After the qualitative leap GPT-5 made over GPT-4o, version 5.4 doubled down on multi-step reasoning, tool use, and code generation.
It has the broadest integration ecosystem on the market, through ChatGPT, the API, and the GPT marketplace. For teams already on OpenAI tools or who need quick access to plugins and ready-made automations, GPT-5.4 is still the easiest on-ramp.
Strengths:
- Best ecosystem of tools and integrations (plugins, Assistants API)
- Excellent at code generation and debugging
- ChatGPT interface widely adopted by teams
- High-precision math and scientific reasoning
Weaknesses:
- Smaller context window than Gemini (128k tokens on the standard tier)
- Higher per-token cost on long tasks
- Tends to hallucinate in highly specific domains
Claude Opus 4.7, Anthropic’s Reasoning Specialist
Claude Opus 4.7 is Anthropic’s flagship model in 2026. Built on the principles of Constitutional AI, it shines at tasks demanding long-horizon reasoning, faithful adherence to complex instructions, and analysis of long documents.
For developers and professionals who need a reliable model in critical workflows — legal review, code audits, technical reports, Opus 4.7 delivers the lowest rate of omission and instruction drift among the three.
Strengths:
- Best at following long, complex instructions
- Lowest factual hallucination rate of the three
- Excellent for code analysis, refactoring, and technical review
- More honest about its own limits and uncertainty
- 200k-token context window with high fidelity
Weaknesses:
- Higher per-token cost on the Opus tier
- Can be overly cautious on creative tasks
- No native video or audio support (text, image, and code only)
Benchmark Comparison
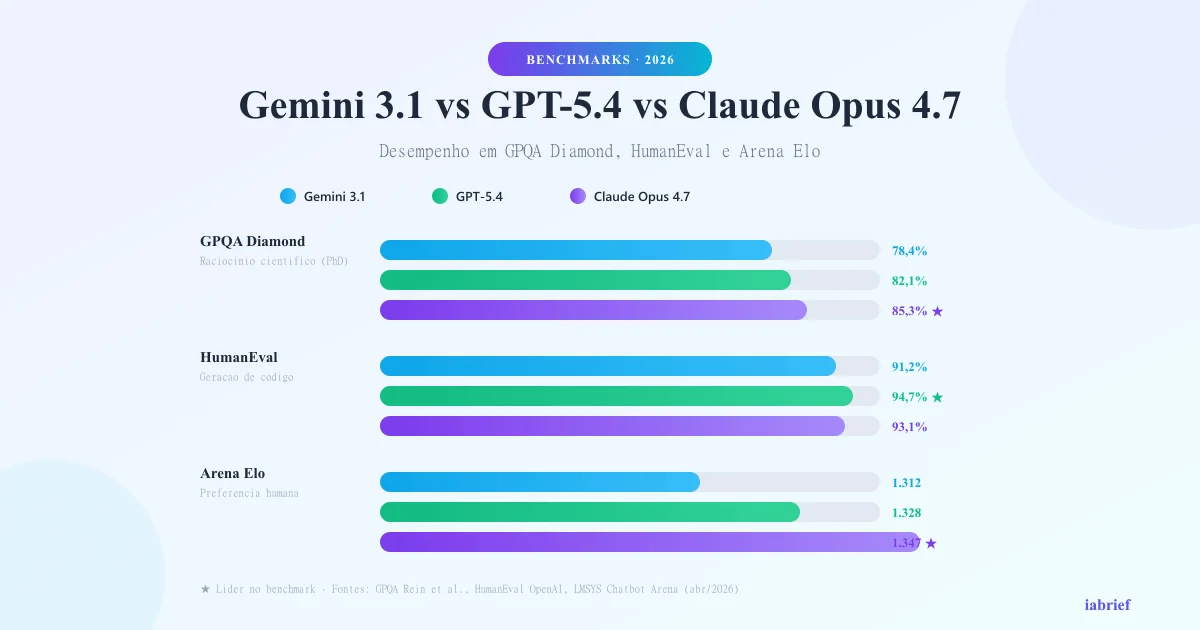
The benchmarks below are the ones most widely used by the research community and enterprises to evaluate language models:
| Benchmark | What it measures | Gemini 3.1 | GPT-5.4 | Claude Opus 4.7 |
|---|---|---|---|---|
| GPQA Diamond | Advanced scientific reasoning (PhD-level) | 78.4% | 82.1% | 85.3% |
| HumanEval | Code generation and correction | 91.2% | 94.7% | 93.1% |
| MMLU | Multidisciplinary knowledge | 89.6% | 90.8% | 91.4% |
| MATH | Mathematical problem solving | 86.3% | 91.2% | 89.7% |
| Arena Elo | Human preference in conversation | 1,312 | 1,328 | 1,347 |
| LongBench | Long-context comprehension | 94.1% | 87.3% | 91.8% |
Sources: GPQA, Rein et al. (2024), updated Q1 2026; HumanEval, OpenAI benchmark suite; MMLU — Hendrycks et al.; Arena Elo, LMSYS Chatbot Arena, April 2026.
Reading the numbers:
- Claude Opus 4.7 leads on scientific reasoning (GPQA), broad knowledge (MMLU), and human preference (Arena Elo)
- GPT-5.4 leads on coding (HumanEval) and math (MATH)
- Gemini 3.1 leads on long-context tasks (LongBench), thanks to its 2M-token window
Pricing Comparison (API, April 2026)
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Gemini 3.1 Ultra | $7.00 | $21.00 |
| GPT-5.4 | $10.00 | $30.00 |
| Claude Opus 4.7 | $15.00 | $75.00 |
Claude Opus 4.7 is the priciest sticker, but its precision lowers the total cost on workflows that would otherwise need extra retries and rework.
Which Model Should You Pick? Ideal Use Cases

Use Gemini 3.1 if you:
- Need to process large volumes of documents or video at once
- Already use Google Workspace and want native integration with Docs, Sheets, and Meet
- Work with multimodal data analysis (spreadsheets + images + text)
- Are building applications on Google Cloud with Vertex AI
Use GPT-5.4 if you:
- Want the broadest ecosystem of plugins, tools, and integrations
- Need a strong model for code generation and review
- Your team already uses ChatGPT and you want a low learning curve
- Work with math, data science, and quantitative modeling
Use Claude Opus 4.7 if you:
- Need high fidelity in following complex instructions
- Work with legal documents, contracts, technical reports, or audits
- Are building AI agents that must be reliable across many steps
- Precision matters more than per-token cost
What About Autonomous AI Agents?
A growing trend in 2026 is using models in multi-agent systems, where several models collaborate on long, complex tasks. In that scenario:
- Claude Opus 4.7 stands out as the “orchestrator” (the central agent coordinating the others), thanks to its ability to follow complex plans without drifting
- GPT-5.4 shines as a “worker” specialized in coding and tool calling
- Gemini 3.1 is ideal as the long-context analysis and document triage agent
The pick can shift inside the same pipeline, depending on the subtask.
The Verdict: There Is No Absolute “Best” Model
The answer to “what’s the best AI model in 2026?” is: it depends on what you need.
- Claude Opus 4.7 wins on reasoning, instruction following, and reliability
- GPT-5.4 wins on coding, math, and integration ecosystem
- Gemini 3.1 wins on long context and native multimodality
For most professionals using AI at work, the smarter play in 2026 isn’t picking a single model, it’s using the right model for each type of task. APIs from Anthropic, OpenAI, and Google make that flexibility affordable.
If you have to pick just one to start: Claude Opus 4.7 for analysis and complex reasoning, GPT-5.4 for coding and automations, Gemini 3.1 for projects involving large multimodal datasets.
FAQ — Frequently Asked Questions
Which AI model has the largest context in 2026?
Gemini 3.1, with a 2-million-token window.
Is Claude Opus 4.7 better than GPT-5.4?
It depends on the task. Claude Opus 4.7 leads on scientific reasoning and human preference; GPT-5.4 leads on coding and math.
Which AI model is cheapest in 2026?
Gemini 3.1 has the lowest cost among the three premium models.
Is Claude Opus 4.7 worth paying more for?
For critical workflows where precision and reliability matter (legal, audit, autonomous agents), the higher cost pays for itself in lower error rates.
Article produced in April 2026. Benchmarks based on public data available at the time of publication.
Related reading
To go deeper, we recommend these iabrief articles:
- OpenAI’s $852 Billion Valuation in 2026: The Largest Private Funding Round in History
- Week in AI: agents at work, Gemini in cars and AI beating doctors (May 3, 2026)
- How to Use Google Veo 3.1 to Create AI Videos: Step-by-Step Tutorial (2026)
Official sources
For deeper context, see the official sources and authoritative references below: