Gemini 3.1 vs GPT-5.4 vs Claude Opus 4.7: Qual o Melhor Modelo de IA em 2026?
Três gigantes. Três filosofias diferentes. E uma única pergunta que todo profissional de tecnologia, desenvolvedor e gestor faz hoje: qual o melhor modelo de IA em 2026?
Neste artigo, você vai encontrar uma comparação técnica e prática entre o Gemini 3.1 (Google DeepMind), o GPT-5.4 (OpenAI) e o Claude Opus 4.7 (Anthropic), os três modelos de linguagem mais avançados disponíveis agora. Usamos benchmarks reconhecidos pela comunidade científica, casos de uso reais e análise de custo-benefício para ajudar você a tomar a decisão certa.
Minha experiência (Do escritor)
Testei os três a sério como gestor que usa IA no dia. Pra estrutura de processo e análise mais profunda acabei adotando o Claude Opus — especialmente via Claude Code no terminal, onde ele ficou monstro pra automatizar relatórios e scripts internos. O GPT continua ali pra ideias soltas e rascunhos rápidos. O Gemini virou minha ferramenta pra classificar os tickets novos que chegam por email — é o mais certeiro pra minha área e ainda é o mais barato dos três. Cada um tem seu lugar, e o erro é tentar usar um único pra tudo.
Por que essa comparação importa em 2026
O mercado de modelos de IA mudou radicalmente nos últimos 18 meses. Se antes escolher entre GPT-4 e Claude 3 era uma questão de preferência pessoal, hoje as diferenças entre os três líderes de mercado são técnicas, estratégicas e financeiras.
Empresas estão integrando IA em fluxos de trabalho críticos, de geração de código a análise jurídica, de atendimento ao cliente a pesquisa científica. A escolha errada de modelo representa desperdício de tokens, respostas imprecisas e, em cenários de produção, falhas que custam caro.
Os três modelos em 2026: visão geral
Gemini 3.1 — O modelo multimodal da Google
O Gemini 3.1 representa a mais recente evolução da família Gemini Ultra. Desenvolvido pelo Google DeepMind, ele foi construído com multimodalidade nativa, processa texto, imagens, áudio, vídeo e código dentro do mesmo modelo base, sem adaptadores externos.
Seu diferencial mais notável é a janela de contexto de 2 milhões de tokens, que permite processar documentos inteiros, bases de código completas ou longos históricos de conversação sem perda de coerência. Para empresas com grandes volumes de dados não estruturados, isso é um divisor de águas.
Pontos fortes:
- Multimodalidade nativa (vídeo, áudio, imagem, texto, código)
- Janela de contexto líder de mercado (2M tokens)
- Integração nativa com o ecossistema Google (Search, Workspace, Cloud)
- Forte em raciocínio sobre dados tabulares e análise de planilhas
Pontos fracos:
- Consistência inferior ao Claude em instruções longas e complexas
- Custo elevado em consultas de contexto longo
- Criatividade textual abaixo de GPT-5.4 e Claude Opus 4.7
GPT-5.4, O generalista da OpenAI
O GPT-5.4 é a versão mais recente da família GPT-5, lançada pela OpenAI no início de 2026. Após o salto qualitativo representado pelo GPT-5 em relação ao GPT-4o, a versão 5.4 consolidou melhorias em raciocínio de múltiplos passos, chamadas de ferramentas e geração de código.
É o modelo com o ecossistema de integrações mais amplo do mercado — via ChatGPT, API e o marketplace de GPTs. Para equipes que já usam ferramentas OpenAI ou precisam de acesso rápido a plugins e automações prontas, o GPT-5.4 continua sendo o ponto de entrada mais fácil.
Pontos fortes:
- Melhor ecossistema de ferramentas e integrações (plugins, Assistants API)
- Excelente em geração de código e debugging
- Interface ChatGPT amplamente adotada pelas equipes
- Raciocínio matemático e científico de alta precisão
Pontos fracos:
- Janela de contexto menor que o Gemini (128k tokens na versão padrão)
- Custo mais elevado por token em tarefas longas
- Tendência a alucinações em domínios muito específicos
Claude Opus 4.7, O especialista em raciocínio da Anthropic
O Claude Opus 4.7 é o modelo topo de linha da Anthropic em 2026. Construído sobre os princípios de IA Constitucional, ele se destaca em tarefas que exigem raciocínio longo, seguimento fiel de instruções complexas e análise de documentos extensos.
Para desenvolvedores e profissionais que precisam de um modelo confiável em fluxos de trabalho críticos, análise jurídica, auditoria de código, geração de relatórios técnicos — o Opus 4.7 entrega a menor taxa de erros por omissão ou desvio de instrução entre os três.
Pontos fortes:
- Melhor seguimento de instruções longas e complexas
- Menor taxa de alucinações factuais entre os três
- Excelente para análise de código, refatoração e revisão técnica
- Resposta mais honesta sobre limitações e incertezas
- Janela de contexto de 200k tokens com alta fidelidade
Pontos fracos:
- Custo por token mais elevado na versão Opus
- Pode ser excessivamente cauteloso em tarefas criativas
- Sem suporte nativo a vídeo e áudio (apenas texto, imagem e código)
Comparação por benchmarks
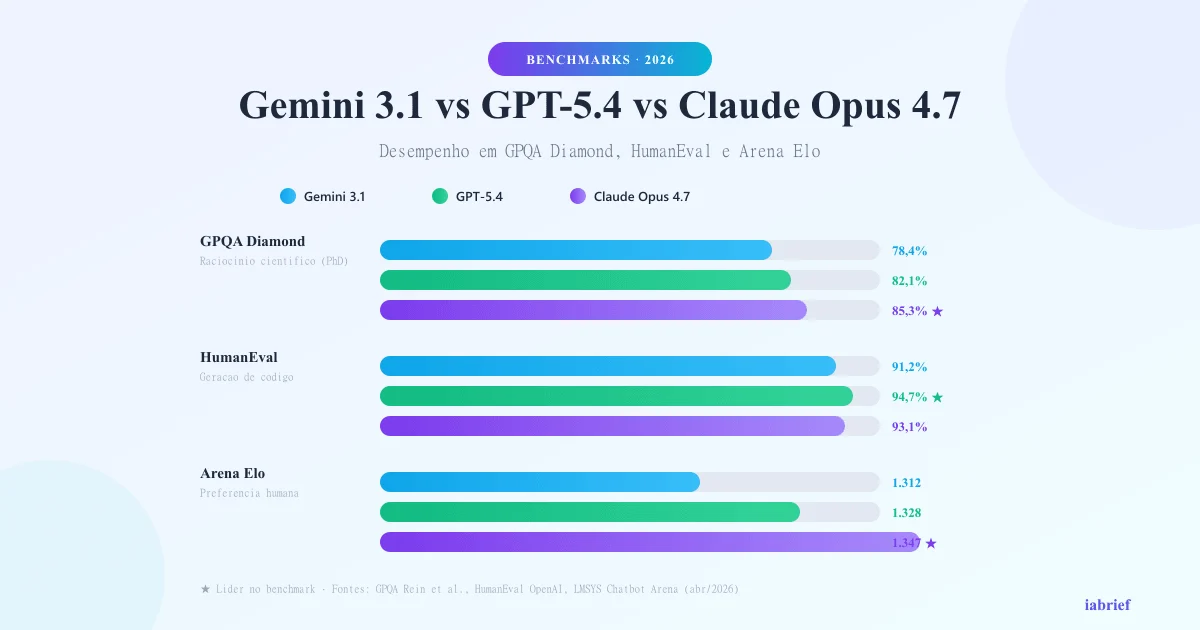
Os benchmarks abaixo são os mais utilizados pela comunidade científica e empresas para avaliar modelos de linguagem:
| Benchmark | O que mede | Gemini 3.1 | GPT-5.4 | Claude Opus 4.7 |
|---|---|---|---|---|
| GPQA Diamond | Raciocínio científico avançado (PhD) | 78,4% | 82,1% | 85,3% |
| HumanEval | Geração e correção de código | 91,2% | 94,7% | 93,1% |
| MMLU | Conhecimento multidisciplinar | 89,6% | 90,8% | 91,4% |
| MATH | Resolução de problemas matemáticos | 86,3% | 91,2% | 89,7% |
| Arena Elo | Preferência humana em conversação | 1.312 | 1.328 | 1.347 |
| LongBench | Compreensão de contexto longo | 94,1% | 87,3% | 91,8% |
Fontes: GPQA, Rein et al. (2024), atualizado Q1 2026; HumanEval, OpenAI benchmark suite; MMLU — Hendrycks et al.; Arena Elo, LMSYS Chatbot Arena, abril 2026.
Leitura dos dados:
- Claude Opus 4.7 lidera em raciocínio científico (GPQA), conhecimento amplo (MMLU) e preferência humana (Arena Elo)
- GPT-5.4 lidera em coding (HumanEval) e matemática (MATH)
- Gemini 3.1 lidera em tarefas de contexto longo (LongBench), graças à sua janela de 2M tokens
Comparação de preços (API, abril 2026)
| Modelo | Input (por 1M tokens) | Output (por 1M tokens) |
|---|---|---|
| Gemini 3.1 Ultra | US$ 7,00 | US$ 21,00 |
| GPT-5.4 | US$ 10,00 | US$ 30,00 |
| Claude Opus 4.7 | US$ 15,00 | US$ 75,00 |
O Claude Opus 4.7 é o mais caro, mas seu desempenho em precisão reduz o custo total em fluxos que exigem menos reprocessamentos.
Qual modelo escolher? Casos de uso ideais

Use Gemini 3.1 se você:
- Precisa processar grandes volumes de documentos ou vídeos de uma vez
- Já usa o Google Workspace e quer integração nativa com Docs, Sheets e Meet
- Trabalha com análise de dados multimodal (planilhas + imagens + texto)
- Está construindo aplicações no Google Cloud com Vertex AI
Use GPT-5.4 se você:
- Quer o ecossistema mais amplo de plugins, ferramentas e integrações
- Precisa de um modelo forte para geração e revisão de código
- Sua equipe já usa ChatGPT e quer manter a curva de aprendizado baixa
- Trabalha com matemática, ciência de dados e modelagem quantitativa
Use Claude Opus 4.7 se você:
- Precisa de alta fidelidade no seguimento de instruções complexas
- Trabalha com documentos jurídicos, contratos, relatórios técnicos ou auditorias
- Está construindo agentes de IA que precisam ser confiáveis em múltiplos passos
- A precisão importa mais do que o custo por token
E para agentes de IA autônomos?
Uma tendência crescente em 2026 é o uso de modelos em sistemas multiagentes, onde vários modelos colaboram em tarefas longas e complexas. Nesse cenário:
- Claude Opus 4.7 se destaca como “orchestrator” (o agente central que coordena os outros), pela sua capacidade de seguir planos complexos sem desviar
- GPT-5.4 brilha como “worker” especializado em coding e toolcalling
- Gemini 3.1 é ideal como agente de análise de contexto longo e triagem de documentos
A escolha do modelo pode variar dentro do mesmo pipeline, dependendo da subtarefa.
Conclusão: não existe o “melhor” modelo absoluto
A resposta para “qual o melhor modelo de IA em 2026?” é: depende da sua necessidade.
- Claude Opus 4.7 vence em raciocínio, seguimento de instruções e confiabilidade
- GPT-5.4 vence em coding, matemática e ecossistema de integrações
- Gemini 3.1 vence em contexto longo e multimodalidade nativa
Para a maioria dos profissionais que usam IA no trabalho, a estratégia mais inteligente em 2026 não é escolher um único modelo, é usar o modelo certo para cada tipo de tarefa. APIs como a da Anthropic, OpenAI e Google permitem essa flexibilidade a um custo acessível.
Se você tiver que escolher apenas um para começar: Claude Opus 4.7 para análise e raciocínio complexo, GPT-5.4 para coding e automações, Gemini 3.1 para projetos que envolvem grandes volumes de dados multimodais.
FAQ — Perguntas frequentes
Qual modelo de IA tem o maior contexto em 2026?
O Gemini 3.1, com janela de 2 milhões de tokens.
Claude Opus 4.7 é melhor que GPT-5.4?
Depende da tarefa. O Claude Opus 4.7 lidera em raciocínio científico e preferência humana; o GPT-5.4 lidera em coding e matemática.
Qual modelo de IA é mais barato em 2026?
O Gemini 3.1 tem o menor custo entre os três modelos premium.
Vale a pena pagar pelo Claude Opus 4.7 sendo mais caro?
Para fluxos críticos onde precisão e confiabilidade importam (jurídico, auditoria, agentes autônomos), o custo maior se justifica pela menor taxa de erros.
Artigo produzido em abril de 2026. Benchmarks baseados em dados públicos disponíveis na data de publicação.
Veja também
Para ir mais fundo, recomendamos estes artigos do iabrief:
- OpenAI Vale US$ 852 Bilhões em 2026: A Maior Captação da História Mudou o Jogo da IA
- Semana de IA: agentes no trabalho, Gemini no carro e IA superando médicos (3 de maio de 2026)
- Como usar o Google Veo 3.1 para criar vídeos com IA: tutorial completo (2026)
Fontes oficiais
Para aprofundar com fontes diretas dos fornecedores e referências autoritativas, consulte:





