IA Multimodal: O Que É e Como Usar em 2026
Você já imaginou ter um assistente capaz de ouvir uma reunião, analisar um gráfico e ainda responder suas perguntas por escrito, tudo ao mesmo tempo? Isso não é ficção científica. É o que a IA multimodal já faz em 2026.
Se você acompanha o mundo da inteligência artificial, provavelmente já ouviu esse termo. Mas o que exatamente significa? E, mais importante: como isso afeta você, que trabalha com marketing, criação de conteúdo ou gestão de um negócio?
Neste artigo, você vai entender o que é IA multimodal, como ela funciona na prática, quais são as principais ferramentas disponíveis hoje e como começar a aplicá-la no seu dia a dia.
O Que É IA Multimodal?
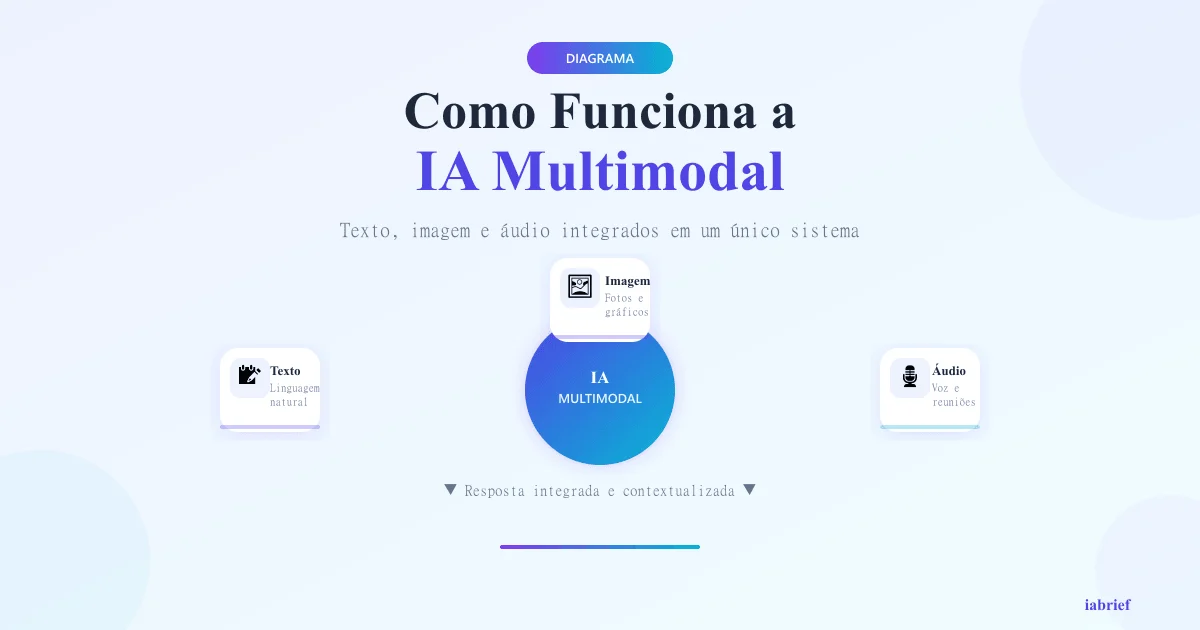
A IA multimodal é um tipo de inteligência artificial capaz de processar e combinar diferentes tipos de dados ao mesmo tempo, como texto, imagem, áudio, vídeo e dados numéricos.
Ao contrário das IAs tradicionais, que eram construídas para lidar com apenas um tipo de informação (por exemplo: só texto ou só imagem), os modelos multimodais entendem o mundo de forma mais parecida com a humana: integrando múltiplos sentidos e fontes de informação para chegar a respostas mais completas e precisas.
Pense assim: quando você conversa com alguém, não usa apenas palavras. Você interpreta expressões faciais, tom de voz, gestos. A IA multimodal replica essa capacidade no ambiente digital — ela “vê”, “ouve” e “lê” ao mesmo tempo.
Segundo a consultoria Gartner, 40% das aplicações de IA generativa em 2026 já são multimodais, um salto enorme comparado a anos anteriores, quando a maioria lidava apenas com texto.
Como a IA Multimodal Funciona?
Para entender o funcionamento, é útil conhecer as três modalidades principais que esses sistemas integram:
Processamento de Texto
A base de quase toda IA moderna. Modelos de linguagem como GPT-4o, Gemini e Claude processam linguagem natural com alta precisão, respondendo perguntas, resumindo documentos, gerando conteúdo e muito mais.
Em um sistema multimodal, o texto é uma das “entradas”, mas o modelo também sabe correlacionar o que leu com o que viu ou ouviu.
Interpretação de Imagem
Modelos multimodais conseguem analisar fotos, gráficos, documentos digitalizados, prints de tela e muito mais. Você pode enviar uma imagem de um contrato e pedir para a IA identificar as cláusulas mais importantes. Ou mostrar um gráfico de vendas e pedir análise.
Ferramentas como o GPT-4o e o Gemini 2.0 já realizam isso com excelência, inclusive lendo texto dentro de imagens (OCR integrado).
Análise de Áudio
A modalidade mais recente a se consolidar em modelos de grande escala. O GPT-4o foi um dos primeiros a processar áudio diretamente — sem transcrever antes, como faziam os sistemas anteriores. Isso reduz a perda de informação (tom de voz, pausas, ênfases) e torna as respostas mais contextualizadas.
Na prática, você pode enviar um trecho de uma reunião gravada e pedir um resumo com pontos de ação. Ou descrever um problema falando em voz alta e receber uma análise detalhada.
Ferramentas de IA Multimodal Disponíveis em 2026
 ferramentas de IA multimodal em 2026" />
ferramentas de IA multimodal em 2026" />
O mercado de IA multimodal evoluiu muito nos últimos dois anos. Aqui estão as principais ferramentas disponíveis hoje:
GPT-4o (OpenAI)
A referência do setor. O GPT-4o processa texto, imagem e áudio de forma unificada, não como módulos separados, mas como uma só arquitetura integrada. Tem a maior base de desenvolvedores e integrações de terceiros do mercado. É a escolha padrão para quem quer um modelo versátil e com bom suporte.
Melhor para: criação de conteúdo, análise de documentos, assistentes de voz, chatbots multimodais.
Gemini 2.0 (Google DeepMind)
O modelo da Google se destaca pela integração nativa com o ecossistema de produtividade: Gmail, Google Docs, Sheets e Drive. Se a sua equipe vive nesses produtos, o Gemini tem vantagem competitiva clara. Também é excelente para analisar documentos longos com imagens embutidas.
Melhor para: empresas que usam Google Workspace, processamento de documentos corporativos.
Claude Sonnet 4.6 (Anthropic)
O Claude é amplamente reconhecido como o modelo mais previsível e com menos alucinações em tarefas estruturadas. Sua arquitetura de segurança (Constitutional AI) o torna ideal para aplicações sensíveis. Também suporta imagem e texto com alta qualidade.
Melhor para: análise de dados sensíveis, jurídico, saúde, tarefas que exigem alta precisão.
Sora 2.0 (OpenAI)
Focado em geração de vídeo a partir de texto e imagem. Permite criar vídeos profissionais com prompts descritivos, sendo muito útil para criadores de conteúdo e equipes de marketing.
Melhor para: criação de vídeos, produção de conteúdo visual em escala.
Ferramentas no-code multimodais
Plataformas como Canva AI, Adobe Firefly e Runway ML já incorporaram capacidades multimodais em interfaces amigáveis, sem necessidade de programação. Você descreve o que quer, faz upload de referências visuais e a IA entrega o resultado.
Casos de Uso Práticos por Área
Marketing e Criação de Conteúdo
- Análise de concorrência visual: envie prints de anúncios concorrentes e peça análise de estratégia
- Criação de conteúdo multicanal: gere texto, imagem e roteiro de vídeo a partir de um único briefing
- Legendas e transcrições automáticas: transforme podcasts ou lives em artigos, threads e posts
- Testes de landing page: mostre um print da página e receba sugestões de otimização de copy e layout
Empreendedorismo e Negócios
- Análise de relatórios: envie PDFs com gráficos e tabelas e receba insights em texto corrido
- Atendimento ao cliente multimodal: chatbots que entendem imagens enviadas pelo usuário (ex: foto de um produto com defeito)
- Apresentações automáticas: descreva seu produto e receba slides estruturados com imagens sugeridas
- Análise de contratos: identifique riscos em documentos digitalizados sem precisar de um advogado para leitura inicial
Saúde
A IA multimodal está transformando o diagnóstico médico: sistemas analisam imagens de exames (raio-X, MRI), relatórios clínicos e histórico do paciente em texto para sugerir diagnósticos mais precisos e tratamentos personalizados. Isso não substitui o médico — mas acelera decisões e reduz erros.
Educação
Plataformas educacionais já usam IA multimodal para criar experiências personalizadas: o aluno pode enviar uma foto de um exercício manuscrito e receber correção e explicação detalhada. Ou fazer perguntas em voz alta enquanto assiste a um vídeo.
Como Começar a Usar IA Multimodal no Seu Negócio
Você não precisa ser desenvolvedor para começar. Siga estes passos:
1. Identifique um processo que combina múltiplos tipos de dados
Pense em tarefas do seu dia a dia que envolvem texto E imagem, ou texto E áudio. Por exemplo: reuniões gravadas que viram atas, e-mails com prints de problemas, relatórios com gráficos.
2. Escolha a ferramenta certa para o seu contexto
Se você usa Google Workspace, comece pelo Gemini. Se quer criar conteúdo, o GPT-4o com DALL-E integrado é forte. Se precisa de precisão em documentos sensíveis, experimente o Claude.
3. Comece com prompts simples e multimodais
Teste enviar uma imagem junto com uma pergunta. Ou um áudio com um pedido de resumo. Observe a qualidade da resposta e ajuste conforme necessário.
4. Automatize os fluxos que funcionarem
Após validar manualmente, use ferramentas como Make (Integromat), Zapier ou n8n para automatizar o processo, por exemplo, transcrever reuniões automaticamente toda semana.
5. Meça o impacto
Tempo economizado, redução de erros, volume de conteúdo produzido. A IA multimodal deve gerar resultado mensurável, não é apenas uma ferramenta “legal de ter”.
O Futuro da IA Multimodal
A tendência para os próximos anos é clara: a IA multimodal vai se tornar o padrão, não a exceção. Modelos que só processam texto serão substituídos por sistemas que percebem o mundo de forma integrada.
O próximo passo é a IA multimodal em tempo real: assistentes que observam a tela do seu computador, escutam sua reunião e intervêm com sugestões quando necessário — sem você precisar fazer nenhum upload.
Para quem está construindo negócios digitais agora, entender e dominar a IA multimodal não é diferencial competitivo, é requisito básico. Quem dominar essa tecnologia nos próximos 12 a 18 meses terá uma vantagem enorme sobre quem ainda está preso ao texto puro.
Conclusão
A IA multimodal representa uma mudança fundamental na forma como as máquinas entendem informação, e, por consequência, na forma como você pode usar a tecnologia no seu negócio.
Ela não é uma tendência distante. Já está disponível, é acessível e está sendo adotada por empresas de todos os tamanhos. A questão não é mais “se” você vai usar — é “quando” e “como”.
Se você quer começar agora, escolha uma ferramenta (GPT-4o, Gemini ou Claude), identifique um processo no seu negócio que combina texto com imagem ou áudio, e faça o primeiro teste ainda hoje. Os resultados costumam surpreender.
Fontes oficiais
Para aprofundar com fontes diretas dos fornecedores e referências autoritativas, consulte:
