Melhor IA 2026: Gemini 3.5 Flash x GPT-5.5 Instant x Claude Opus 4.8 (Comparativo Atualizado)
Em três semanas de maio de 2026, os três maiores laboratórios de IA do mundo lançaram novos modelos de ponta. A OpenAI tornou o GPT-5.5 Instant o modelo padrão do ChatGPT em 5 de maio. O Google apresentou o Gemini 3.5 Flash no I/O, em 19 de maio. E a Anthropic respondeu com o Claude Opus 4.8 em 28 de maio, reivindicando o topo dos benchmarks. Se você se perguntava qual é a melhor IA que 2026 oferece hoje, a resposta mudou de novo — e essa edição existe para destrinchar exatamente o que mudou.
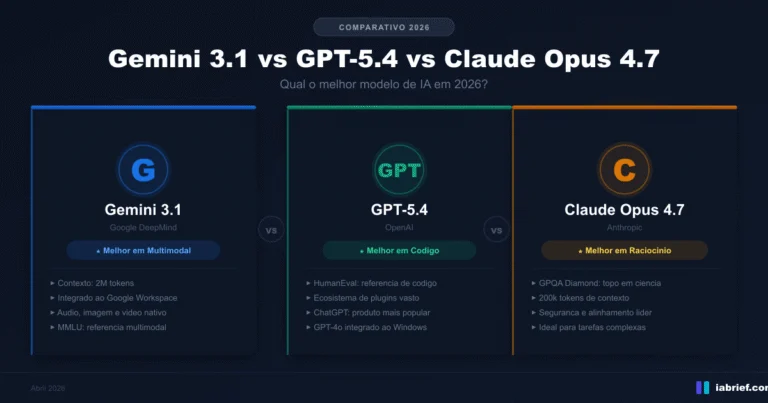
Este é um comparativo atualizado. Em fevereiro publicamos a análise dos modelos da geração anterior — Gemini 3.1, GPT-5.4 e Claude Opus 4.7 — no nosso guia sobre o melhor modelo de IA em 2026. Aqui o foco é diferente: três modelos novos, três filosofias de produto que ficaram ainda mais distintas, e uma escolha que depende muito mais do seu caso de uso do que de um único número de benchmark. Sem hype, com o que importa.
O Que Mudou Desde o Comparativo Anterior
A geração anterior era uma disputa relativamente direta entre três modelos “topo de linha” comparáveis em preço e ambição. A geração de maio de 2026 quebrou essa simetria. Cada empresa escolheu otimizar para algo diferente:
- O Google desceu o Flash para competir onde antes só o Pro jogava — barateando a fronteira para agentes e código de alto volume.
- A OpenAI apostou no produto, não no benchmark: o GPT-5.5 Instant é sobre confiabilidade no dia a dia (menos alucinação) e memória que realmente lembra de você.
- A Anthropic dobrou a aposta em ser a referência de capacidade bruta, mantendo o Opus como o modelo “para quando o resultado precisa estar certo”.
O resultado é que comparar esses três pelo mesmo eixo ficou enganoso. Vamos olhar cada um, depois os benchmarks lado a lado, e fechar com recomendações por tarefa.
Gemini 3.5 Flash — A Fronteira Ficou Barata
O Gemini 3.5 Flash, lançado no Google I/O em 19 de maio de 2026, é o primeiro modelo da família 3.5. O nome “Flash” historicamente indicava o modelo rápido e barato da linha Gemini — mas dessa vez o Google fez algo incomum: o Flash agora supera o Gemini 3.1 Pro (o premium do ano passado) em vários benchmarks exigentes.
Os números são consistentes. No MCP Atlas (confiabilidade de uso de ferramentas em escala) ele marca 83,6% contra 78,2% do 3.1 Pro. No Finance Agent v2 salta para 57,9% contra 43,0%. Na prática, o trabalho que exigia o modelo caro do ano passado agora roda num modelo posicionado como intermediário — e, segundo o Google, com saída de tokens cerca de 4x mais rápida.
Pontos fortes:
- Multimodalidade nativa (texto, imagem, áudio e vídeo no mesmo modelo)
- Janela de contexto de 1 milhão de tokens, com até 64K de saída
- Forte em uso de ferramentas, fluxos agênticos e código de alto volume
- Velocidade de saída muito alta — ideal para tarefas em lote e produção
Pontos fracos:
- O preço subiu: US$ 1,50 por 1M de tokens de entrada e US$ 9 de saída — o triplo do Gemini 3 Flash, que custava US$ 0,50 e US$ 3. O “Flash barato” ficou para trás.
- Em raciocínio puro e exames difíceis, ainda fica atrás do 3.1 Pro (que lidera em Humanity’s Last Exam e ARC-AGI-2)
- Não é o modelo a escolher quando você precisa do raciocínio mais profundo possível
A leitura: o Gemini 3.5 Flash é a melhor relação capacidade-velocidade-preço para quem constrói coisas em escala. Não é o mais inteligente da mesa, mas é o que faz mais por menos.
GPT-5.5 Instant — Confiabilidade e Memória Viram o Produto
A OpenAI tomou um caminho diferente. O GPT-5.5 Instant virou o modelo padrão do ChatGPT em 5 de maio de 2026, substituindo o GPT-5.3 Instant. E o destaque do lançamento não foi um recorde de benchmark — foi confiabilidade e memória.
No benchmark interno de alucinação da OpenAI (medicina, direito e finanças, onde respostas erradas têm consequências reais), a taxa caiu de 18,7% para 8,9% — uma redução relativa de 52,5%. Em conversas que usuários haviam sinalizado por erros factuais, o modelo produziu 37,3% menos afirmações imprecisas. Vale o alerta: esses são números internos da OpenAI, com uso de ferramentas habilitado, e ainda dependem de validação independente.
O segundo destaque é a memória. O GPT-5.5 Instant pode usar a ferramenta de busca para recuperar conversas passadas, arquivos enviados e o seu Gmail, gerando respostas personalizadas com o seu próprio histórico. E há uma camada de transparência: o ChatGPT mostra qual informação foi usada e de qual fonte, com a possibilidade de corrigir ou apagar. Em benchmarks objetivos, o modelo marca 81,2 no AIME 2025 (contra 65,4 do antecessor) e 76,0 no MMMU-Pro multimodal.
Pontos fortes:
- Menos alucinação em domínios sensíveis — o ganho mais útil para uso diário
- Memória que busca conversas, arquivos e Gmail, com transparência de fonte
- É o padrão do ChatGPT, então a maioria dos usuários já está nele sem precisar configurar nada
- Ecossistema mais amplo de integrações e ferramentas do mercado
Pontos fracos:
- Em benchmarks de capacidade bruta (coding agêntico, raciocínio com ferramentas), fica atrás do Opus 4.8
- A integração com Gmail e arquivos pessoais levanta questões legítimas de privacidade
- Preço de API mais salgado: a OpenAI dobrou o GPT-5.5 para US$ 5 de entrada e US$ 30 de saída por 1M de tokens
A leitura: o GPT-5.5 Instant é o modelo de conversa e produtividade pessoal mais polido. Para quem vive dentro do ChatGPT, a combinação de menos erros e memória contextual é o tipo de melhoria que se sente todo dia.
Claude Opus 4.8 — A Referência de Benchmark
A Anthropic lançou o Claude Opus 4.8 em 28 de maio de 2026 e, pelos números públicos, ele reassumiu o posto de modelo mais capaz da mesa. A própria comunidade de avaliação independente o classificou como o novo #1.
Os destaques são no trabalho que exige rigor. No SWE-bench Verified (correção de bugs reais em repositórios) ele marca 88,6%; no SWE-bench Pro, mais difícil, 69,2% — contra 58,6% do GPT-5.5 e 64,3% do Opus 4.7. No GDPval-AA, que mede trabalho de conhecimento do mundo real, atinge 1.890 de Elo, cerca de 121 pontos à frente do GPT-5.5 (1.769). E no Humanity’s Last Exam com ferramentas (57,9%), lidera por uma margem estreita sobre OpenAI e Google. No GPQA Diamond fica em 93,6%, estatisticamente empatado com os concorrentes — ou seja, o conhecimento científico bruto já é commodity no topo.
Pontos fortes:
- Melhor desempenho em coding agêntico e correção de bugs reais (SWE-bench)
- Líder em trabalho de conhecimento (GDPval-AA) e em raciocínio com ferramentas
- Confiável em tarefas longas e multi-passo — o modelo “para quando precisa estar certo”
- Modo rápido (Fast Mode) ficou cerca de 3x mais barato que na geração anterior
Pontos fracos:
- Custo de saída ainda alto: US$ 5 de entrada e US$ 25 de saída por 1M de tokens (Fast Mode dobra)
- Não lidera em todos os eixos — no Finance Agent v2, por exemplo, o Gemini 3.5 Flash fica à frente (57,9% contra 53,9%)
- Multimodalidade mais limitada que o Gemini (foco em texto, imagem e código)
A leitura: o Opus 4.8 é a referência quando o erro custa caro — auditoria de código, agentes confiáveis, análise técnica e jurídica. É o modelo que você usa quando o resultado importa mais que o custo por token.
Benchmarks Lado a Lado
A tabela abaixo reúne os números públicos mais comparáveis de maio de 2026. Importante: cada laboratório reporta benchmarks parcialmente diferentes, então nem toda célula tem dado oficial divulgado para os três. Onde falta número confiável, deixamos a comparação qualitativa.
| Benchmark | O que mede | Gemini 3.5 Flash | GPT-5.5 (Instant) | Claude Opus 4.8 |
|---|---|---|---|---|
| SWE-bench Verified | Correção de bugs reais | — | — | 88,6% |
| SWE-bench Pro | Coding agêntico difícil | — | 58,6% | 69,2% |
| GDPval-AA (Elo) | Trabalho de conhecimento | 1.656 | 1.769 | 1.890 |
| Humanity’s Last Exam (c/ tools) | Raciocínio de fronteira | — | 52,2% | 57,9% |
| GPQA Diamond | Ciência nível PhD | — | — | 93,6% (empate técnico) |
| Finance Agent v2 | Agente financeiro | 57,9% | — | 53,9% |
| Terminal-Bench 2.1 | Tarefas de terminal | 76,2% | — | 74,6% |
| MCP Atlas | Uso de ferramentas em escala | 83,6% | — | — |
Fontes: páginas oficiais de Anthropic, Google DeepMind e OpenAI; Artificial Analysis; Vellum; OpenRouter. Números de maio de 2026, predominantemente de avaliações internas dos próprios laboratórios — leia como direção, não como verdade absoluta.
Leitura dos dados:
- Claude Opus 4.8 lidera em coding (SWE-bench), trabalho de conhecimento (GDPval) e raciocínio com ferramentas (HLE)
- Gemini 3.5 Flash lidera em agente financeiro e brilha em uso de ferramentas e multimodalidade — entregando isso a uma fração do custo
- GPT-5.5 Instant fica no meio em benchmark bruto, mas ganha onde não há tabela: confiabilidade no uso real e memória
Comparação de Preços (API, maio/junho de 2026)
| Modelo | Entrada (por 1M tokens) | Saída (por 1M tokens) |
|---|---|---|
| Gemini 3.5 Flash | US$ 1,50 | US$ 9,00 |
| Claude Opus 4.8 | US$ 5,00 | US$ 25,00 |
| GPT-5.5 (API padrão) | US$ 5,00 | US$ 30,00 |
O Gemini 3.5 Flash é, de longe, o mais barato — embora tenha triplicado em relação ao Gemini 3 Flash. Opus 4.8 e GPT-5.5 estão em patamar parecido na entrada, com o GPT-5.5 mais caro na saída. Tenha em mente que GPT-5.5 e Opus 4.8 têm variantes (Pro, Fast, Priority, Batch) com preços bem diferentes.
A queda de preço da fronteira é uma tendência maior do que esses três modelos. Para entender por que inferência está ficando mais barata, vale ler nossa análise sobre o TurboQuant, o algoritmo do Google que reduz o custo de inferência.
Qual Escolher? Recomendações por Caso de Uso
Para código
Claude Opus 4.8. Lidera com folga em SWE-bench Verified (88,6%) e SWE-bench Pro (69,2%), os benchmarks que mais se aproximam de trabalho real de engenharia. Se o orçamento aperta e o volume é alto, o Gemini 3.5 Flash é a alternativa pragmática: bom em código, rápido e muito mais barato.
Para pesquisa e raciocínio
Claude Opus 4.8 novamente, pela liderança em Humanity’s Last Exam com ferramentas e em GDPval-AA. Para pesquisa que envolve muitos documentos, imagens ou vídeo de uma vez, o Gemini 3.5 Flash e sua janela de 1M de tokens com multimodalidade nativa são imbatíveis em custo.
Para conversa e produtividade pessoal
GPT-5.5 Instant. É onde a OpenAI ganha: menos alucinação em assuntos sensíveis e memória que recupera suas conversas, arquivos e Gmail. Para o usuário que vive no ChatGPT, é o mais útil no dia a dia — e já vem como padrão.
Para custo
Gemini 3.5 Flash. A US$ 1,50/US$ 9 por 1M de tokens, entrega capacidade de fronteira pela menor conta da mesa. Para startups, automações e qualquer coisa em volume, é a escolha óbvia de custo-benefício.
A estratégia mais inteligente em 2026 segue sendo a mesma de sempre: não casar com um modelo só. Use o Opus para o que precisa estar certo, o Flash para o que precisa ser barato e rápido, e o GPT-5.5 para a conversa do dia a dia. Quem está montando fluxos com vários modelos colaborando vai gostar do nosso panorama sobre agentes de IA autônomos em 2026.
Perguntas Frequentes
Qual é a melhor IA em 2026?
Não existe uma só. Pelos benchmarks públicos de maio de 2026, o Claude Opus 4.8 é o mais capaz em coding e raciocínio. Mas o GPT-5.5 Instant é melhor para conversa e produtividade pessoal, e o Gemini 3.5 Flash ganha em custo e velocidade. A melhor IA depende da tarefa.
O Gemini 3.5 Flash é melhor que o Gemini 3.1 Pro?
Em vários benchmarks agênticos e multimodais, sim — o Flash novo supera o Pro do ano passado, como em MCP Atlas e Finance Agent v2. Mas o 3.1 Pro ainda lidera em alguns testes de raciocínio puro, como Humanity’s Last Exam e ARC-AGI-2.
A memória do GPT-5.5 Instant é segura?
A OpenAI adicionou uma camada de transparência que mostra qual informação foi usada e de qual fonte (conversa, arquivo ou Gmail), com opção de corrigir ou apagar. Ainda assim, conectar Gmail e arquivos pessoais é uma decisão de privacidade que cada usuário deve avaliar conscientemente.
Qual modelo é o mais barato?
O Gemini 3.5 Flash, a US$ 1,50 por 1M de tokens de entrada e US$ 9 de saída — bem abaixo do Opus 4.8 (US$ 5/US$ 25) e do GPT-5.5 (US$ 5/US$ 30 na API padrão).
Vale a pena pagar mais pelo Claude Opus 4.8?
Para fluxos onde o erro custa caro — auditoria de código, agentes autônomos confiáveis, análise técnica e jurídica — sim. A liderança em SWE-bench e GDPval-AA reduz reprocessamentos e erros, o que costuma compensar o custo por token mais alto.
Os números de benchmark são confiáveis?
São úteis como direção, não como verdade absoluta. A maioria vem de avaliações internas dos próprios laboratórios e ainda aguarda validação independente. Cada empresa também reporta benchmarks parcialmente diferentes, o que dificulta a comparação perfeita.
O Que Acompanhar a Partir de Agora
A geração de maio de 2026 mostrou que a corrida deixou de ser por um único “modelo mais inteligente” e passou a ser por especialização: capacidade bruta (Anthropic), produto e confiabilidade (OpenAI) e custo-eficiência na fronteira (Google). Três coisas para monitorar nos próximos meses: validações independentes que confirmem (ou desmintam) os benchmarks internos; a resposta de preço — se a queda do Flash forçar OpenAI e Anthropic a baratear; e como a memória conectada ao Gmail e a arquivos vai amadurecer em privacidade e regulação.
Para acompanhar as próximas atualizações, assine a newsletter do iabrief — 1 email por semana, sem hype, com o que importa.