TurboQuant: Como o Google Quebrou a Barreira do Custo da IA em 2026
O que é o TurboQuant?
Em março de 2026, o Google anunciou o TurboQuant, um algoritmo de compressão desenvolvido pelo Google DeepMind que promete mudar radicalmente a economia da inteligência artificial. Em termos simples: ele consegue encolher a “memória de trabalho” de grandes modelos de linguagem (LLMs) em até 6 vezes, ao mesmo tempo em que acelera o processamento em até 8 vezes, tudo isso sem perda mensurável de qualidade nas respostas.
O algoritmo foi apresentado na conferência ICLR 2026 e rapidamente se tornou um dos tópicos mais discutidos no mundo de IA, não só por sua performance técnica, mas pelo impacto imediato que causou no mercado de chips de memória.
Se você é desenvolvedor, gestor de TI ou investe no setor de tecnologia, entender o TurboQuant deixou de ser opcional.
O problema que o TurboQuant resolve
Para entender a relevância do TurboQuant, é preciso compreender um gargalo central na operação de LLMs: o KV Cache (Key-Value Cache).
Quando um modelo de linguagem processa uma conversa longa ou um documento extenso, ele precisa armazenar temporariamente informações sobre cada token (palavra ou fragmento de texto) processado. Esse espaço de armazenamento temporário é o KV Cache, e ele cresce linearmente com o tamanho do contexto.
O problema é que os valores armazenados no KV Cache costumam ser representados em ponto flutuante de 16 bits. Isso consome quantidades enormes de memória de GPU, o recurso mais caro e escasso da infraestrutura de IA atual. Modelos maiores, contextos mais longos e requisições simultâneas multiplicam essa demanda de forma brutal.
O resultado: empresas precisam de dezenas de GPUs caras (como a NVIDIA H100) só para servir um modelo em produção, tornando a IA acessível apenas para quem pode pagar a conta.
Como funciona o TurboQuant: a técnica por trás da compressão extrema
Quantização sem overhead
Métodos tradicionais de quantização (compressão dos valores numéricos) tentam resolver o problema, mas introduzem um novo custo: precisam calcular e armazenar constantes de quantização para cada bloco de dados, o que adiciona de 1 a 2 bits extras por número. No fim das contas, o ganho real de compressão é modesto.
O TurboQuant resolve isso de forma elegante por meio de um processo em duas etapas:
Etapa 1, Rotação aleatória dos dados: O algoritmo aplica uma rotação matemática nos vetores do KV Cache. Essa rotação simplifica a geometria dos dados, tornando os valores muito mais fáceis de comprimir com alta qualidade usando quantizadores escalares padrão — sem precisar de constantes adicionais.
Etapa 2, Correção de erro com QJL: O pequeno resíduo de erro deixado pela primeira etapa é tratado com o algoritmo QJL (Quantized Johnson-Lindenstrauss), que funciona como um verificador matemático de erros. Com apenas 1 bit extra, o QJL elimina o viés de compressão, garantindo que o resultado final seja estatisticamente indistinguível do modelo original em precisão total.
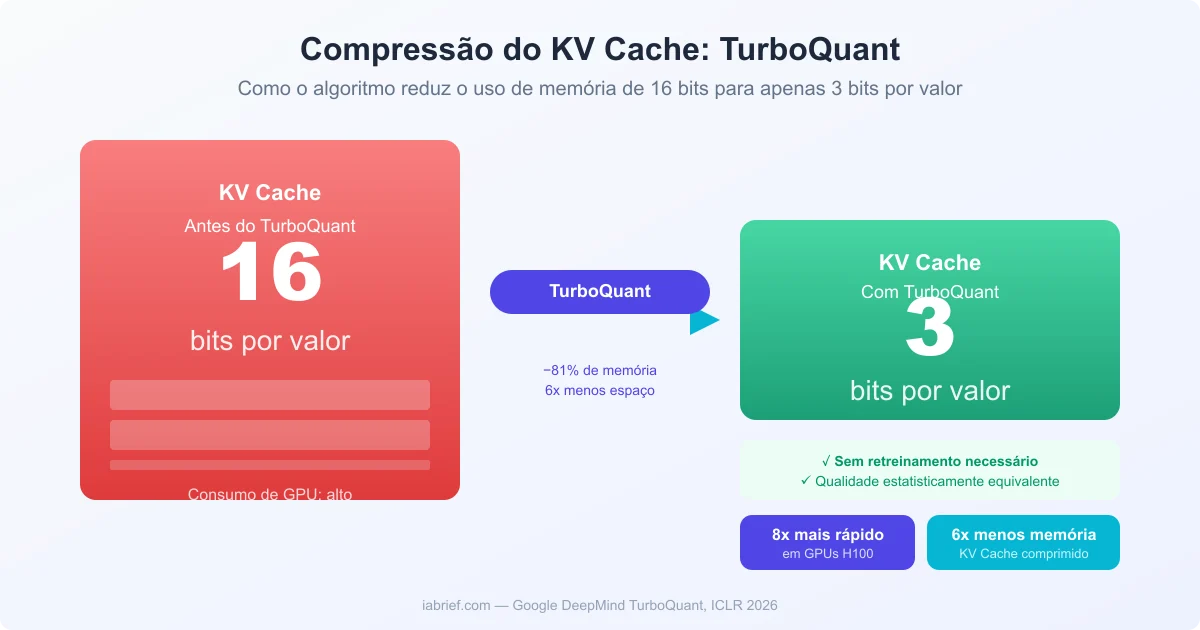
O resultado prático: os valores do KV Cache são comprimidos de 16 bits para apenas 3 bits por valor, uma redução de mais de 80% no tamanho — sem que o modelo precise ser retreinado ou ajustado.
Sem retreinamento, sem risco
Um diferencial crítico do TurboQuant é ser training-free e data-oblivious: não exige retreinamento do modelo, não precisa de datasets específicos e pode ser aplicado a qualquer LLM existente, incluindo modelos já ajustados (fine-tuned) para casos de uso específicos. As empresas não precisam abrir mão do que investiram em customização.
6x menos memória: o que isso significa na prática
A compressão de 6x no KV Cache não é apenas um número impressionante em papel de pesquisa. Ela se traduz em impactos concretos para quem opera IA em produção:
- Contextos maiores no mesmo hardware: Um servidor que antes suportava contextos de 32 mil tokens pode, com TurboQuant, processar contextos de até 192 mil tokens sem adicionar um único chip.
- Mais requisições simultâneas: A memória liberada permite atender muito mais usuários ao mesmo tempo com a mesma infraestrutura.
- IA local mais poderosa: Rodar modelos grandes em hardware consumer (como uma RTX 4090 com 24 GB de VRAM) torna-se viável para contextos que antes eram impossíveis sem GPUs de data center.
- Aceleração de 8x: A compressão também acelera o cálculo dos attention logits em até 8x em GPUs H100, reduzindo a latência das respostas.
Custo de inferência pode cair mais de 50%
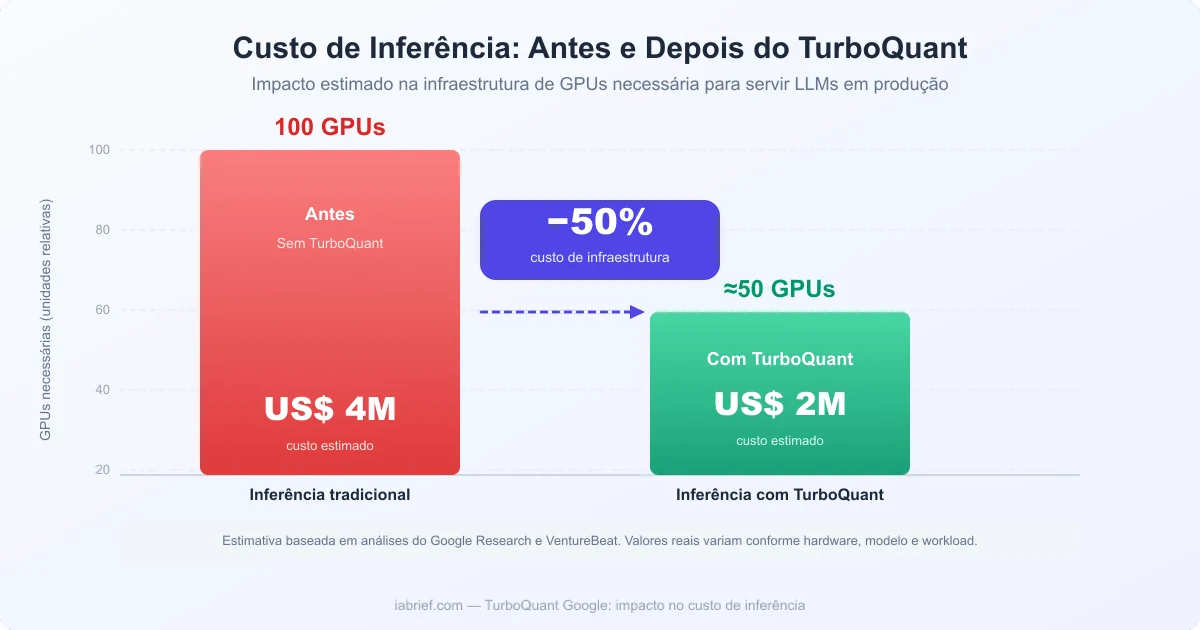
O impacto financeiro é onde o TurboQuant se torna verdadeiramente disruptivo.
Integrar o TurboQuant em servidores de inferência pode reduzir o número de GPUs necessárias para servir aplicações de contexto longo, potencialmente cortando custos de cloud compute em mais de 50%, segundo análises da VentureBeat e do Google Research.
Para ter uma ideia de escala: uma GPU H100 SXM custa entre US$ 30.000 e US$ 40.000 no mercado, além do custo de energia, refrigeração e manutenção. Se uma empresa que roda IA em produção precisa de 100 GPUs, o TurboQuant poderia, em teoria, permitir que ela opere com 50 ou menos, mantendo o mesmo throughput.
Para startups e PMEs que usam APIs de IA (como OpenAI, Google ou Anthropic), a esperança é que os provedores repassem parte dessa eficiência em forma de preços menores por token. Isso já é uma tendência: o custo de inferência de modelos top-tier caiu mais de 90% nos últimos dois anos, e avanços como o TurboQuant devem acelerar ainda mais essa curva.
TurboQuant e o mercado de hardware: por que as ações despencaram
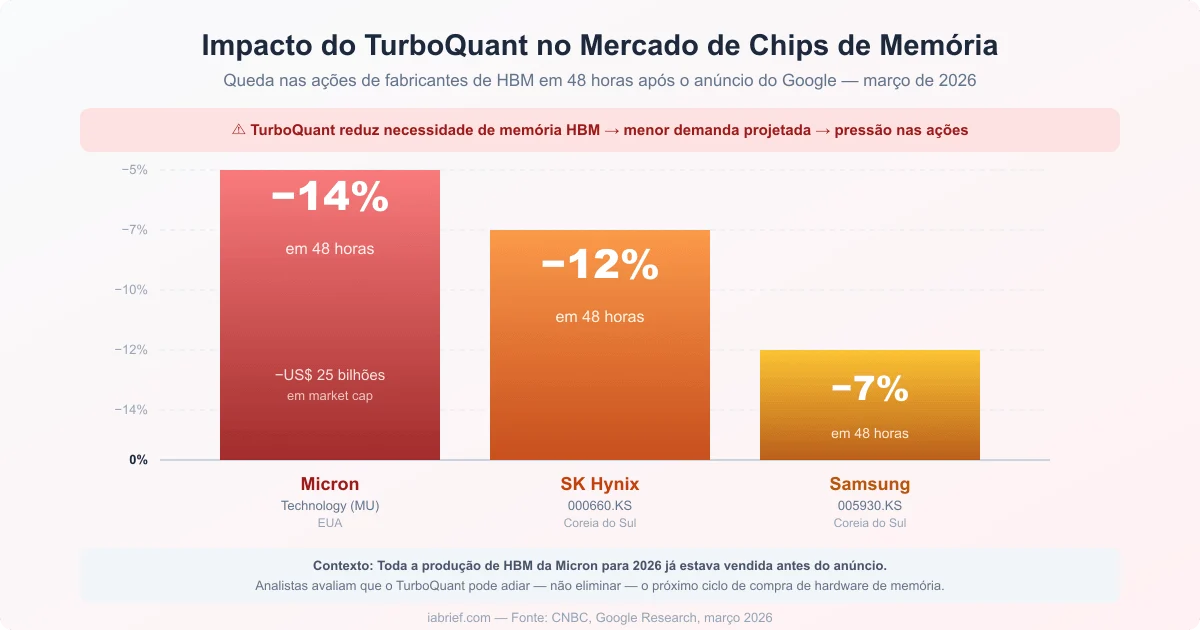
A reação do mercado financeiro ao anúncio do TurboQuant foi imediata e contundente.
A Micron Technology — principal fornecedora de HBM (High Bandwidth Memory) para servidores de IA, viu suas ações caírem 14% em 48 horas, apagando mais de US$ 25 bilhões em capitalização de mercado. A SK Hynix caiu 12% e a Samsung recuou 7% nas bolsas asiáticas.
A lógica do mercado é direta: se a IA precisa de 6x menos memória física por operação, a demanda projetada por chips HBM encolhe. Para fabricantes que apostaram pesado na expansão de capacidade produtiva, isso é uma mudança de tese.
Porém, analistas mais conservadores apontam que a situação é mais complexa. A Micron, por exemplo, tinha toda a sua produção de HBM para 2026 já vendida antes do anúncio. A demanda por IA continua crescendo em ritmo acelerado. O que o TurboQuant pode fazer é adiar, não eliminar, o próximo grande ciclo de compra de hardware de memória.
Para investidores em tech, o sinal é claro: eficiências de software podem comprimir margens de hardware. Diversificação setorial é mais importante do que nunca.
O que muda para devs, gestores de TI e pequenas empresas
Para desenvolvedores
O TurboQuant abre possibilidades práticas que antes exigiam hardware premium:
- Rodar modelos como LLaMA 4 ou Gemini com contextos longos em servidores mais modestos
- Construir aplicações RAG (Retrieval-Augmented Generation) com contextos maiores sem explodir o budget de GPU
- Experimentar localmente com modelos de maior porte em hardware consumer
O código do TurboQuant deve ser integrado gradualmente às principais frameworks de inferência (como vLLM, TensorRT-LLM e Ollama), mas já existem implementações experimentais disponíveis.
Para gestores de TI
Se a sua empresa já paga por APIs de IA ou roda modelos próprios on-premise, é hora de revisar os contratos e benchmarks. As métricas de custo por requisição que você calculou há seis meses podem estar desatualizadas.
Além disso, vale monitorar quando os principais provedores de cloud (AWS, Azure, GCP) integrarem TurboQuant nativamente em seus serviços gerenciados de inferência — isso pode representar uma oportunidade de renegociação ou migração de workloads.
Para pequenas empresas que usam IA
O impacto mais tangível para PMEs é indireto, mas real: com a infraestrutura de inferência ficando mais eficiente, os preços de APIs de IA tendem a continuar caindo. Ferramentas que hoje custam centenas de dólares por mês em tokens podem se tornar economicamente acessíveis para negócios menores.
A IA deixa de ser monopólio de quem tem datacenters.
Limitações: o que o TurboQuant não resolve
Transparência é importante. O TurboQuant é um avanço significativo, mas tem fronteiras claras:
1. Inferência, não treinamento: O algoritmo comprime o KV Cache durante a inferência. O treinamento de modelos continua exigindo quantidades massivas de memória de alta banda, o TurboQuant não muda essa equação.
2. Ainda em fase de adoção: Apesar da publicação científica, o TurboQuant ainda não está integrado nativamente nos produtos de IA mais utilizados. A transição de laboratório para produção em larga escala leva tempo.
3. Não resolve o custo de treinamento: Para empresas que treinam seus próprios modelos, o gargalo de custo ainda é o pré-treinamento, e aí o TurboQuant não ajuda.
4. Benefícios dependem de implementação: Obter os 6x de compressão e 8x de speedup requer implementação cuidadosa e hardware compatível (especialmente GPUs H100+). Resultados em hardware mais antigo podem variar.
Conclusão: o futuro da IA se torna mais acessível
O TurboQuant é mais do que uma publicação técnica elegante. Ele representa uma mudança concreta na economia da IA: mais inteligência com menos hardware, a um custo menor, disponível para mais pessoas e empresas.
Para devs, a mensagem é: acompanhe a adoção nas frameworks que você já usa. Para gestores de TI, é o momento de revisitar o planejamento de infraestrutura. Para investidores, o recado é que eficiências de software continuarão a pressionar o hardware — e quem souber se posicionar antes da curva sairá na frente.
A IA 6x mais barata não é ficção científica. Com o TurboQuant, ela começa a se tornar realidade.
Alt texts sugeridos para imagens:
- Imagem 1: “Diagrama do algoritmo TurboQuant mostrando compressão do KV Cache de 16 bits para 3 bits”
- Imagem 2: “Comparativo de custo de inferência antes e depois do TurboQuant Google”
- Imagem 3: “Impacto do TurboQuant nas ações da Micron Technology em março de 2026”
Links externos sugeridos: