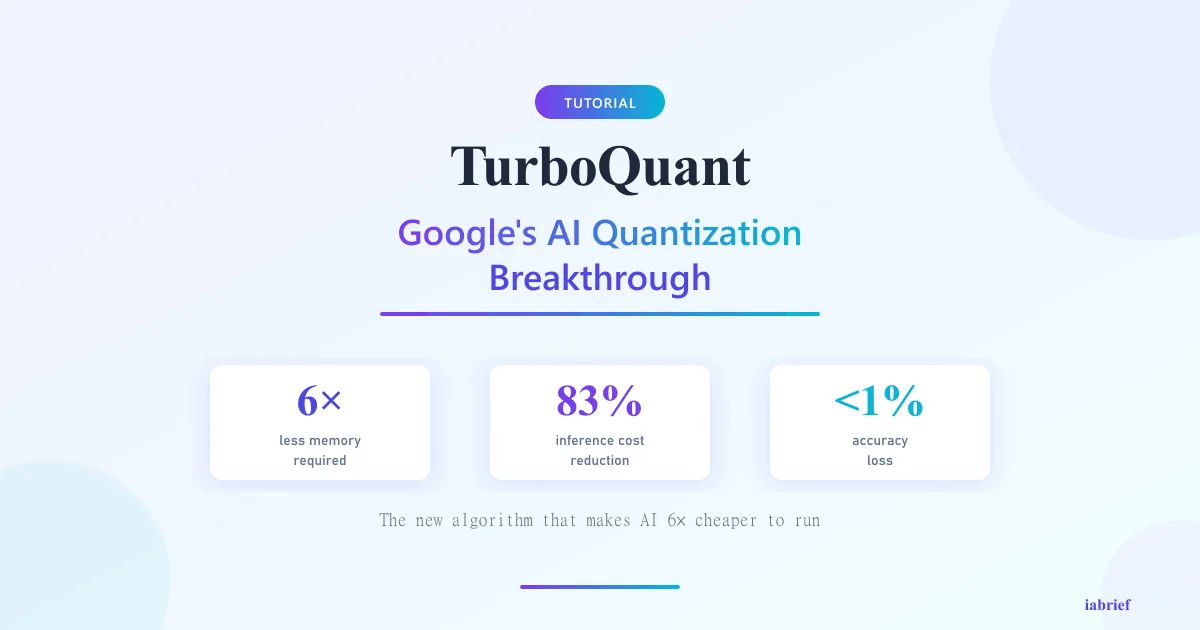
TurboQuant: How Google Broke the AI Cost Barrier in 2026
What Is TurboQuant?
In March 2026, Google announced TurboQuant, a compression algorithm developed by Google DeepMind that promises to redraw the economics of artificial intelligence. In plain terms: it can shrink the “working memory” of large language models (LLMs) by up to 6x while accelerating processing by up to 8x, all with no measurable loss in answer quality.
The algorithm was presented at ICLR 2026 and quickly became one of the most discussed topics in the AI world, not only for its technical performance but for the immediate impact it had on the memory chip market.
If you’re a developer, IT leader, or tech investor, understanding TurboQuant is no longer optional.
The Problem TurboQuant Solves
To grasp why TurboQuant matters, you have to understand a central bottleneck in running LLMs: the KV Cache (Key-Value Cache).
When a language model processes a long conversation or a long document, it has to temporarily store information about every token (word or text fragment) it has handled. That temporary store is the KV Cache, and it grows linearly with context length.
The catch: the values in the KV Cache are usually represented in 16-bit floating point. That eats huge amounts of GPU memory, the most expensive and scarce resource in today’s AI infrastructure. Larger models, longer contexts, and concurrent requests all multiply that demand brutally.
The result: companies need dozens of pricey GPUs (like the NVIDIA H100) just to serve one model in production, putting AI within reach only for those who can pay the bill.
How TurboQuant Works: The Technique Behind the Extreme Compression
Quantization with no overhead
Traditional quantization methods (compressing numerical values) try to solve the problem, but they introduce a new cost: they need to compute and store quantization constants for each block of data, which adds 1 to 2 extra bits per number. The net compression gain ends up being modest.
TurboQuant solves this elegantly through a two-step process:
Step 1, Random rotation of the data: The algorithm applies a mathematical rotation to the KV Cache vectors. That rotation simplifies the geometry of the data, making the values much easier to compress at high quality with standard scalar quantizers — without needing additional constants.
Step 2, Error correction with QJL: The small residual error left by step one is handled by the QJL (Quantized Johnson-Lindenstrauss) algorithm, which acts like a mathematical error checker. With just 1 extra bit, QJL eliminates compression bias, ensuring the final result is statistically indistinguishable from the original full-precision model.
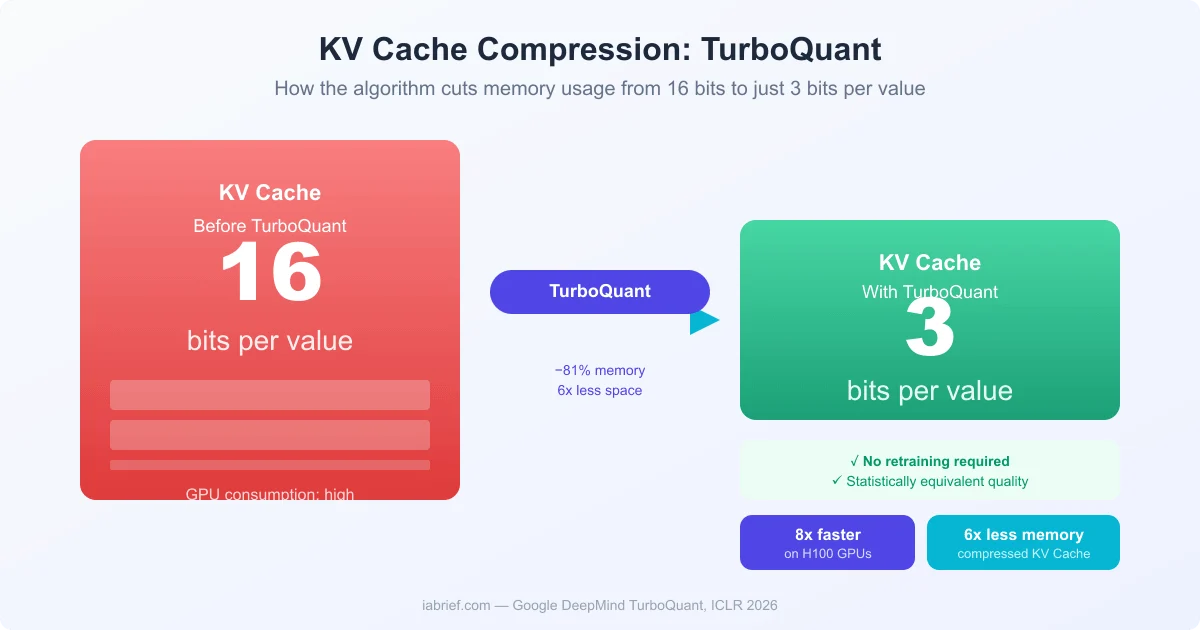
The practical outcome: KV Cache values get compressed from 16 bits down to just 3 bits per value, over 80% size reduction, with no need to retrain or fine-tune the model.
No retraining, no risk
A critical edge of TurboQuant is being training-free and data-oblivious: it doesn’t require model retraining, doesn’t need specific datasets, and can be applied to any existing LLM — including models already fine-tuned for specific use cases. Companies don’t have to throw away their customization work.
6x Less Memory: What It Means in Practice
A 6x compression on the KV Cache isn’t just an impressive number on a research paper. It translates into concrete impact for anyone running AI in production:
- Larger contexts on the same hardware: A server that used to support 32k-token contexts can, with TurboQuant, handle contexts of up to 192k tokens without adding a single chip.
- More concurrent requests: The freed memory lets you serve many more users at once on the same infrastructure.
- More powerful local AI: Running large models on consumer hardware (like an RTX 4090 with 24 GB of VRAM) becomes viable for contexts that previously required data center GPUs.
- 8x speedup: The compression also accelerates attention logit computation by up to 8x on H100 GPUs, cutting response latency.
Inference Costs Could Drop by More Than 50%
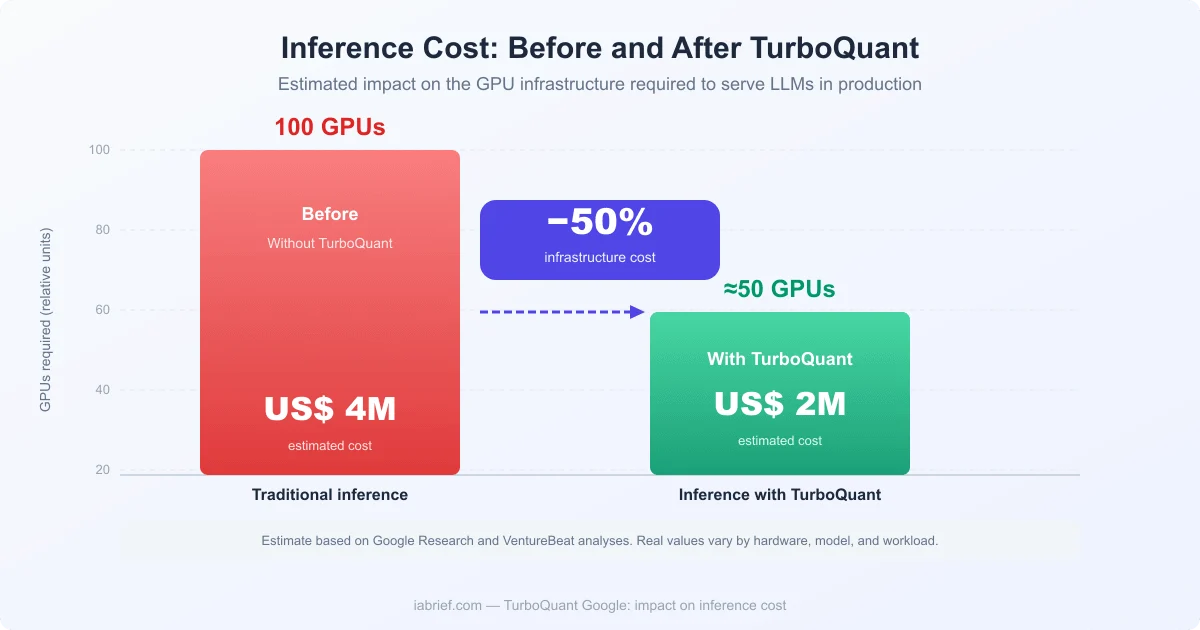
The financial impact is where TurboQuant becomes truly disruptive.
Integrating TurboQuant into inference servers can reduce the number of GPUs needed to serve long-context applications, potentially cutting cloud compute costs by more than 50%, according to analyses from VentureBeat and Google Research.
For a sense of scale: an H100 SXM GPU costs between $30,000 and $40,000 on the market, on top of energy, cooling, and maintenance. If a company running AI in production needs 100 GPUs, TurboQuant could in theory let it operate with 50 or fewer while keeping the same throughput.
For startups and SMBs using AI APIs (OpenAI, Google, Anthropic, etc.), the hope is that providers will pass some of that efficiency through as lower per-token prices. That’s already a trend: top-tier model inference cost has dropped over 90% in the last two years, and breakthroughs like TurboQuant should accelerate that curve further.
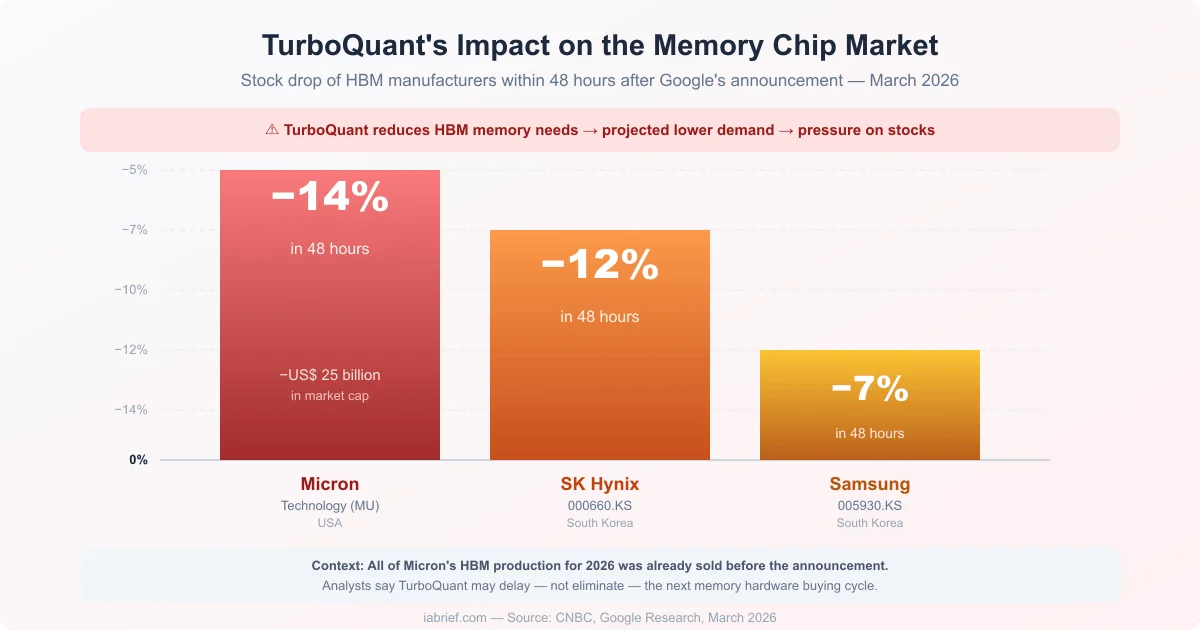
TurboQuant and the Hardware Market: Why the Stocks Crashed
The financial market’s reaction to the TurboQuant announcement was immediate and severe.
Micron Technology, the leading supplier of HBM (High Bandwidth Memory) for AI servers, saw its shares fall 14% in 48 hours, wiping out more than $25 billion in market cap. SK Hynix dropped 12% and Samsung retreated 7% on Asian exchanges.
The market logic is straightforward: if AI needs 6x less physical memory per operation, projected demand for HBM chips shrinks. For manufacturers that bet heavily on expanding production capacity, that’s a thesis-changing event.
That said, more conservative analysts point out the situation is more nuanced. Micron, for instance, had its entire 2026 HBM production sold out before the announcement. AI demand keeps growing at a fast clip. What TurboQuant may do is delay — not eliminate, the next big memory hardware purchase cycle.
For tech investors, the signal is clear: software efficiencies can compress hardware margins. Sector diversification matters more than ever.
What Changes for Devs, IT Leaders, and Small Businesses
For developers
TurboQuant unlocks practical possibilities that previously demanded premium hardware:
- Running models like LLaMA 4 or Gemini with long contexts on more modest servers
- Building RAG (Retrieval-Augmented Generation) applications with larger contexts without blowing up your GPU budget
- Experimenting locally with larger models on consumer hardware
TurboQuant code is expected to land gradually in the major inference frameworks (vLLM, TensorRT-LLM, Ollama), but experimental implementations are already available.
For IT leaders
If your company already pays for AI APIs or runs models on-premise, it’s time to revisit the contracts and benchmarks. The cost-per-request metrics you calculated six months ago may already be out of date.
It’s also worth watching for when major cloud providers (AWS, Azure, GCP) integrate TurboQuant natively into their managed inference services, that could create an opening for renegotiation or workload migration.
For small businesses using AI
The most tangible impact for SMBs is indirect, but real: as inference infrastructure becomes more efficient, AI API prices should keep falling. Tools that today cost hundreds of dollars per month in tokens may become economically accessible to smaller businesses.
AI stops being the monopoly of those with data centers.
Limitations: What TurboQuant Does Not Solve
Transparency matters. TurboQuant is a significant advance, but it has clear limits:
1. Inference, not training: The algorithm compresses the KV Cache during inference. Training models still requires massive amounts of high-bandwidth memory, TurboQuant doesn’t change that equation.
2. Still in early adoption: Despite the scientific publication, TurboQuant is not yet natively integrated into the most widely used AI products. The journey from lab to large-scale production takes time.
3. It doesn’t solve training cost: For companies training their own models, the cost bottleneck is still pre-training — and TurboQuant doesn’t help there.
4. Benefits depend on implementation: Hitting the 6x compression and 8x speedup requires careful implementation and compatible hardware (especially H100+ GPUs). Results on older hardware may vary.
Conclusion: A More Accessible AI Future
TurboQuant is more than an elegant technical paper. It represents a concrete shift in the economics of AI: more intelligence with less hardware, at lower cost, available to more people and companies.
For devs, the message is: track adoption in the frameworks you already use. For IT leaders, it’s time to revisit infrastructure planning. For investors, the takeaway is that software efficiencies will keep pressuring hardware margins, and those who position themselves ahead of the curve will come out ahead.
AI that’s 6x cheaper isn’t science fiction. With TurboQuant, it’s starting to become reality.
Suggested image alt texts:
- Image 1: “Diagram of the TurboQuant algorithm showing KV Cache compression from 16 bits to 3 bits”
- Image 2: “Inference cost comparison before and after TurboQuant by Google”
- Image 3: “Impact of TurboQuant on Micron Technology stock in March 2026”
Suggested external links:
Related reading
To go deeper, we recommend these iabrief articles:





